






芥末堆文,3月9日中午12时,来自于Google的人工智能机器人AlphaGo同韩国棋手李世石展开具有“跨时代意义”的第一场人机大战。比赛持续了近4小时,AlphaGo以人工智能的身份,最终赢得了这场比赛。
李世石,1983年3月2日生于韩国全罗南道,曾于2006、2007、2008均获得韩国围棋大奖—最优秀棋手大奖(MVP),是职业九段选手的世界围棋冠军,此次代表人类出战。本次围棋挑战赛共分为5场,在韩国首尔举行,获胜者将得到一百万美元奖金。
而AlphaGo(阿尔法围棋)是一款由英国谷歌旗下的DeepMind团队开发而成,主要工作原理是“深度学习”,即通过模拟人脑神经网络和对职业棋手棋谱的学习,进行自我博弈,再通过两个不同神经网络“大脑”来决定棋路,曾于去年10月以5:0完胜欧洲围棋冠军、职业二段选手樊麾。这场人类同智能机器人的“世纪之战”,瞬间吸引了众多关注。

从围棋学习谈起,围棋为什么是“人类最后的智力骄傲”?
相对于国际象棋,为什么说围棋是“人类最后的智力骄傲”呢?因为围棋作为一门竞技体育项目,更成体系,逻辑性也更强,更难学习和提升。国际象棋每一步有24种可能性,而围棋以变化反复闻名,按照棋盘上每个交叉点上黑、白、空三种可能性算,棋盘的变化总数可达3的361次方次可能性,而目前的计算机无法对所有走法进行统计和穷举,因此人工智能依然无法玩转围棋界。此次AlphaGo赢得了这场比赛,刷新了围棋界的新纪录,代表人工智能第一次在围棋界,超越了最高水平的专业选手。
围棋作为变化多端的一种竞技类项目,一般认为可以开发智力,拓展思维,具有很强的教育意义和锻炼意义。据悉,中国学习围棋的儿童目前已超1000万人。
机器学习模仿人脑神经模式,所以能“步步为赢“?
在去年10月樊麾同AlphaGo的对弈中,樊麾曾表示,“如果没有人告诉我,我一定不知道它是电脑,它太像人了。它一定是在思考。”此外,樊麾还提到在对弈过程中,AlphaGo不同于人类,完全没有心态的波动变化,且有很强的学习能力。AlphaGo会进行自我学习,采取自我博弈的方式,一旦输了,就会记录下来,下次避免这种下棋方式。通过数据统计和积累,研究出最好的下棋和落子方式。
从1997年美国IBM公司研发的超级计算机“深蓝”战胜了当时世界排名第一的国际象棋大师卡斯帕罗夫后,机器学习的概念再次走进大众视野。不同于人类的学习模型,机器学习是对能通过经验自动改进的计算机算法的研究,特别是如何在经验学习中改善具体算法的性能。除却“深蓝”,2006年,超级计算机“浪潮天梭”也在人机大战中大败5位中国象棋特级大师。
AlphaGo采取的主要工作原理是“深度学习”模式,即拥有多层的人工神经网络及训练它的方法。AlphaGo拥有“策略网络”和“价值网络”两个“大脑”,通过策略网络观察棋盘,决定下一步下棋步骤,而“价值网络”则是在判断对手赢棋可能性的情况下进行落子决定。
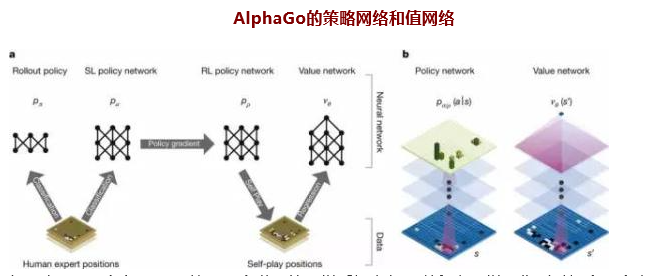 (图片来源:澎湃新闻)
(图片来源:澎湃新闻)
本次AlphaGo的胜利,被认为是深蓝在1997年成功挑战国际象棋的20年后,人工智能取得的又一巨大胜利。自此,人工智能在围棋界,攻破了人类最后的“智力壁垒”,走入了新时代。
