






CVPR作为是全球计算机视觉顶会之一,近年来的论文接收率不超过25%。今年,会议收到了21000名作者的7000篇投稿,经过7400名审稿人和280名区域主席的审查,最终有1600篇论文被接收,接收率约0.24。
而在CVPR 2021 UG2+挑战赛——弱光条件下(半)监督人脸检测赛道中,国内的「TAL-ai」团队以mAP 74.89的高分夺得第一,领先第二名3%。

在弱光条件下,人脸的视觉特征与正常环境中有很大的差异,也就使现有人脸检测算法无法有效工作。
TAL-ai在论文中提出了新的解决方法,研究人员除了在增强图像亮度时结合了两种方法,同时还对正常的图像进行处理来扩展训练集,并将数个检测器组合起来增强对人脸的检测。

https://arxiv.org/pdf/2107.00818.pdf
弱光条件的人脸检测
赛事提供的「DARKFACE」数据集将会被用作作为训练和验证,其中含有6000个低亮度图像,并具有相应的面部注释。最终的测试集则由4000个图像组成。
这些样本取自北京的几条繁忙的街道上,其中包含各种尺度的人脸,其中图像的分辨率为1080×720(从6k×4k下采样)。

极低光线条件的样本,其中红色框线是基准真相
低亮度图像增强
为了增强图像的亮度,论文使用MSRCR方法,同时实现了动态范围压缩、颜色一致性以及亮度再现。

MSRCR方法
此外,还使用了另一种数据驱动亮度增强方法ZeroDCE,将亮度增强任务与深度网络的图像标准曲线进行估计。

ZeroDCE方法
从增强的低光图像中提取显着图Rsaliency,并将其与Rmsrcr融合,从而抑制错误的结果,融合结果R saliency_enhanced:

α=0.3的结果
正常图像的域迁移
论文将WIDERFACE和UFDD预训练集与经过预处理的DARKFACE相结合,从而构建更具鲁棒性的检测器。
考虑到预处理的DARKFACE样本与正常图像之间的领域差距,论文将WIDERFACE和UFDD迁移到与已处理的DARKFACE数据集更相邻的域。
传统的方法是降低正常图像的亮度,添加噪音,然后用MSRCR处理。

传统迁移方法
HLAFace方法则是使用Pix2Pix网络来合成噪声,从而获得由低亮度增强图像和经过域迁移的正常图像组成的训练样本。

HLAFace方法
检测与结果
论文构建的弱光人脸检测框架由两部分组成:级联R-CNN和检测器。并使用Cascade R-CNN作为De-Scribe细节的示例。

训练架构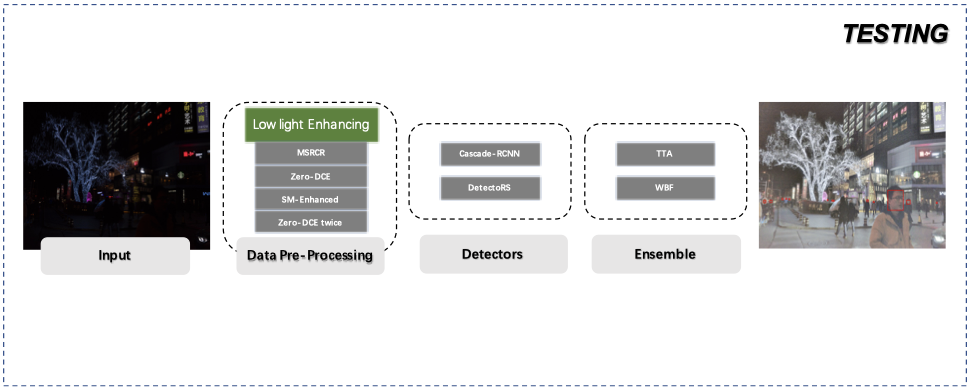

测试架构
数据集拆分
论文将DARKFACE数据集按照每张图片中人脸的数量分成几组,然后随机选择每组中10%的样本作为验证部分,其余90%的数据作为训练部分。
训练策略
论文进行了多尺度训练,调整样本范围从[2160,1440]到[4320,2880],并对其应用大小为[1000,800]的随机裁剪。并且使用图像增强工具来在线处理训练样本,包括随机亮度,颜色抖动等。
此外,还要使用AdamW优化器,初始学习率为0.0001,在27和33个epoch中进行线性衰减,共36个epoch,权重衰减为0.05。
模型重构
特征表示一直是物体检测任务的关键点,而骨干网络对特征表示的能力有非常重要的影响。
因此,论文采用Swin-Transformer和ResNet两个架构。此外,还采用了PAFPN来代替级联R-CNN中的FPN。
在分析了DARKFACE数据集的人脸大小分布后,研究人员注意到小尺寸的人脸占主导地位。因此,论文设置了更多的小锚点来捕捉更多小的人脸。
论文在主干中加入了注意力模块GCnet,从而获得更强大的表征,同时RoI-align模块也被用来预测更精确的边界框。

人脸大小的分布
模型组合
最后,论文用Swin-large、Swin-base、ResNet50等不同的骨架训练Cascade R-CNN和DetectorRS,以获得更好的检测器多样性结果。
论文使用加权边界框融合(WBF)和测试时数据增强(TTA)方法将检测器的预测组合,并在模型组合过程中使用了Soft-NMS。

验证结果
总结
论文在增强图像亮度时结合了两种不同的方法,同时,研究人员对正常图像进行处理,从而获得增强亮度的弱光图像以及经过域迁移的正常图像相结合的训练样本。最后,论文结合了数个检测器来定位人脸的边界框。
参考资料:
https://cvpr2021.ug2challenge.org/leaderboard21_t1.html
https://arxiv.org/pdf/2107.00818.pdf
本文转载自微信公众号“新智元“(ID:AI_era),来源:CVPR 2021 UG2+,编辑好困。文章为作者独立观点,不代表芥末堆立场,转载请联系原作者。
来源:新智元