
芥末堆 吉吉 11 月 11 日
11 月 11 日,在以《创•见•教育新生态》为主题的 GET2016 教育科技大会上,ATA集团副总裁、全美学业CEO刘颖讲述了大数据对教育的两大价值:提升学习成效(效率和效果)、精准匹配人才。
刘颖表示,未来将用“数据”这个关键词驱动他们的业务,也为未来的教育做出贡献。
以下为刘颖演讲重点内容:
两大价值
在刘颖看来大数据对教育的两大价值,其一,提升学习成效,成效包括效率和效果两个方面;其二,精准匹配人才。
1、提升学习成效(效率和效果)
“说到大数据提升学习成效,大家会想到知识图谱、自适应学习、翻转课堂、走班分层教学。”刘颖坦言,其实大家更多的是想以知识(能力)为导向实现个性化学习,实现因材施教。
在她看来,教育本身是违背人性的,所以更多要去思考,能不能用大数据实现对孩子动力系统的改造,大数据提升学习成效,更重要的应该是以动机、个性、情绪为导向的因材施教,比如:自适应练习、在线情绪识别、动机测试、生物反馈诊断、网络行为分析。
2、精准匹配人才
大数据实现了个体才智发展图谱的构建,而才智发展图谱实现人与专业、人与职业的精准匹配。
“大数据链接贯通了个体的学习,到升学,到职业发展。”刘颖表示,这也是ATA接下来,未来的十年二十年一直致力于做的事情,“构建教育与学习、人才和职业的数据中心,通过我们的测评技术、通过我们积累的大数据、通过我们的知识图谱的研究和构建。”
美丽的陷阱
“大数据确实在很大程度上改变了我们的教育,但是大数据虽然很美,也很有价值和意义,但是它也有美丽的陷阱。”刘颖如是说。在她看来,大数据的陷阱主要体现在以下一些方面:
到底需要采集哪些数据?
非文本数据的识别与处理?
数据如何降噪?如何把采集来的数据在评价之前做降噪
教育大数据如何挖掘(建模)?
如何避免数据推论错误?
以下是刘颖演讲实录:
首先我替我们ATA的创始人也是我们的CEO马肖风先生向大家道个歉,他有一个紧急事务要处理无法来参加GET大会,就请我做他的替身在台上为他发表演讲,当然我讲的东西也代表他的观点。
今天我要跟大家分享的话题可能跟刚才新东方、好未来的主题有非常大的关联,ATA作为一家科技型的公司,原来是以考试测评为主营业务,这两年我们也在做着巨大的转型,马总说:“ATA通过考试测评积累了如此大量的数据,最有机会可以成为为教育行业做贡献的一家数据公司。”于是我们开始重新定位ATA的方向,我们未来将用“数据”这个关键词来驱动我们的业务,也会帮助我们未来教育做出更多的贡献。
所以今天我以我自己浅薄的对教育数据的认知来跟大家做一些分享。
我们都知道随着互联网,随着人工智能甚至随着穿戴设备等等这些技术的进步,我们的教育毫无疑问正在进入一个大数据的时代。我们时时刻刻通过互联网收集到大量的数据,这些数据除了以前我们知道的学生的、老师的、所谓人口统计学的数据,还可以借助pad、借助激光笔、借助其他的教学设备搜集老师在教学课堂过程当中的数据。
同样随着过程性学业评价的推广和越来越多地被认知,各种各样的作业场景、练习场景、月考场景、期中期末考试场景的数据也越来越多被汇聚起来。
同时随着刚才我们提到的在线教育的普及,我们可以通过学生、通过老师在线的,尤其是学生在线学习的行为来获得很多具体学习过程中的行为数据。同样我们通过各种移动设备可以搜集到学生在课外、校外的各种各样的数据,零零总总,这里只是稍许列举一二,我们就可以感觉到大数据给我们带来的扑面而来的势力。
面对这样的大数据我也一直在思考,数据对于教育真正的价值到底体现在哪儿?我总结了我的观点,我认为大数据对教育有两重最重要的价值:
大数据带来了我们可以真正提升学生的学习成效,这个成效分为两层含义:学习效率的提升、学习效果的提高。
因为有了精准的数据我们可以实现真正精准的人才评价。
接下来我从这两点分开大家做一些详细的分享。
大数据的第一重价值:提升学习成效
首先我们看教育利用大数据如何可以提升学生的学习成效?听到这个词大家首先想到的是什么?对于大数据对于学习成效的帮助,我想一定是知识图谱、自适应学习、翻转课堂、走班分层教学等等。
>>知识图谱和自适应学习
我觉得很有意思的一件事情是在13、14年我们再、去看知识图谱、自适应学习的时候,觉得是非常新鲜的名词,但是到了15年尤其到了今年年初,如果做教育不提点“知识图谱”不提点“自适应学习”都不敢说自己是做教育的。这个发展就是这么迅速,大家都知道所谓的知识图谱是利用大数据,我们找到不同学科、不同领域它的知识点之间的关联,方便我们去帮助学生做更精准的诊断,进而为他推荐个性化学习的方案。
自适应学习就是在知识图谱这种技术的基础上发展出来的一种个性化学习的方式。
>>翻转课堂
翻转课堂我也不用赘述,其实有了互联网技术翻转课堂成为了一种现实,我们的学生可以在家里先看视频,看各种学习资料提前学习老师将要讲授的内容,同时通过测评让老师提前知道这个孩子在哪些知识点或者技能点方面掌握的是好的,哪些地方还有缺憾。
带着这些问题他们再次走到教室的时候,这时候老师已经不再是讲授知识为主了,而是以辅导、提升以及组织学生讨论,集体来解决问题为主的一种新的翻转式的教学模式。这里所谓的“翻转”可能大家都了解就是以教师为主体转为以学生为主体。这种翻转课堂一定要借助大数据和科技的技术。
>>走班分层教学
最近在国内整个公立体系内也非常火的一件事情就是很多人都在提走班分层教学,因为我们越来越感知到一个大班一个老师没有办法教授,尤其随着现在整个教育评价的一种改革我们的小升初已经没有考试了,没有考试以后很多中学会说,进来的学生是优秀的也有、中等的也有或者一般的也有,当然我指的是不同学科都会有能力的参差不齐,让一个老师面对不同能力层次的孩子讲同样的课程呢,这显然是不合理的。所以很多学校现在开始在实施通过对学生提前的评价,各种不同学科提前的测评来了解学生的特长、特点、学科优势进而给他们进行分班分层的教学,这些都是大数据带给我们的价值。
可是大家有没有感受到,这些时间我们谈很多知识图谱,我们希望把知识点切的越细越好甚至到纳米级别,我们希望把学习路径规划的越精细越好。但是我的感觉大家更多实际上是在以知识能力为导向来实现一种个性化的学习,实现因材施教。
我们想象一个非常理想的场景,一个学生经过评价我给他一个诊断的报告,我知道他有哪些知识点是缺失的,于是我给他推送相应的练习题、微课、学习资料,这是很多教育创业者天天梦想的、理想的模式。可是,有一个场景或者有一个道理大家也是非常熟知的“教育本身是违背人性的”,很少有学生真的特别自觉的想学,我特别希望针对我的薄弱点给我补强推送东西,可是我们更多看到的是你给他了练习、给他了微课,但是他却没有兴趣、没有动力认真把它学好。
所以我们总说教育可能不是知识点的问题,也不是能力点的问题,我们可能更多的、更重要的是我们要去思考,我们能不能够利用大数据来驱动对孩子动力系统的改造?比如是他的学习动机,比如说针对他自己的个性特征为他匹配最适合他个性的内容,比如我们能不能针对孩子当前的情绪状态来进行课程、内容的调节等等。
我亮出第二个观点就是大数据提升学习成效,我认为更重要的实际上是孩子个性化的内驱力,对学习的内驱力的激发,这就是以动力、个性、情绪为导向的因材施教。因此其实我们这些年也看到,我们的教育工作者、我们的大数据工作者也在朝这个方向,利用大数据做着多样化的努力。
>>自适应练习
比如说自适应的练习,目前我看到有很多在线练习的公司,他们采用ARP自适应的出题方式来给学生进行内容的练习,这种练习它的好处是,因为我们都知道自适应的练习它是根据学生的能力程度或者知识掌握程度给孩子出不同的题目,这个过程有点类似查视力表。
各位到医院查视力一般医生不会从上面查起,也不会从底下最小的E字查,他一定先给你看中间“中间的字看得见吗?”看不见往上升一点,看得见就往下降一点。自适应练习就类似这样的过程,学生先出点中等难度的题目,都答对了再加难一点,再答对了再加难一点,答不对的时候我再调容易一些。
这个和自适应学习是两码事,自适应考试是完全以学生的最近发展区来给他出题。这个好处是什么?我记得我跟有一家公司的CEO聊过,他欣喜的发现,原来的学渣也特别热爱做练习了,是因为你始终围绕着他所能达到的,稍微跳一跳就能达到的目标,在出学习的内容或者练习的题目,让学生时刻可以感受到做对以后的成就感。教育学里一直提倡“最近发展区”理论,自适应学习恰好贴合了最近发展区理论的阐述。
>>在线情绪识别
第二我们也看到在线学习已经越来越多的机构利用电脑上的摄像头来对学生学习过程中的情绪状况数据做搜集,并且利用人工智能的方式来识别孩子的面部表情,当摄像头识别到孩子的情绪现在已经非常的烦燥,可能已经有些懈怠的时候,这时候在线学习的内容我们可能会跳转到一个比较轻松或者游戏式的练习当中,让孩子能够放松一下,转换一下他学习的状态和情绪,这也是大数据、人工智能在教育领域的一项很好的应用。
>>动机测试
同时我们也看到,越来越多的学校、越来越多的机构开始关注对学生非认知能力的测评,什么非认知能力?比如他的学习动机、他的学习自信心以及他学习失败以后的归因方式等等,这种测试已经越来越多的被加载到在线学习或课堂学习当中。
>>生物反馈诊断
同时我们还看到,现在有越来越多的穿戴设备已经可以通过搜集人体的生物学信息比如皮电、眼动、声律变异性等等这些指标来实时反馈,用这些数据实时反馈学生或者孩子当前学习的压力状况,他的自控力水平、注意力集中的状态,目前已经有很多的生物反馈设备或者穿戴设备可以做这样的数据采集和数据分析。
>>网络行为分析
随着行为数据大热之后,网络行为数据的分析也在全球越来越多的被很多科学家或者研究所所关注,所以网络行为数据跟学生非认知能力的关联研究也越来越多被展开。我给大家看下面一张图。
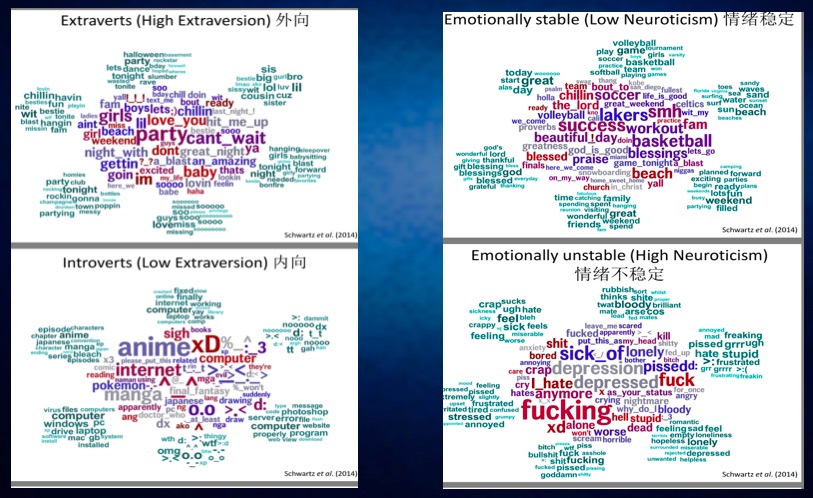
大家可以看到,我在背板上演示了两张图这是英国剑桥大学也是我们合作的一家机构,剑桥大学心理测量中心,它研究什么?它研究在类似微信这样的社交软件中包括家校通,孩子跟老师之间交互过程中每个人不同的用语,比如常提到的单词和他在里边用到的表情、他的各种行为反应和与每个人他个性之间的关系、和他情绪之间的关系。
左图大家可以看到,中间这些单词当然因为是基于英国研究,它提到中间这些单词用的比较多的人往往是个性偏外向的。
下面这张图中间这些单词往往是内倾型或者内向型性格的人,在网络交互过程中间他的行为表现出来的,他可能是内向型的。
右边这张图,上面是一个情绪比较稳定的孩子或者是成人,他可能会用的比较多的单词,在跟人交互交流的过程中。
下面可能是情绪不稳定的人经常会出现的高频单词有哪些。
这些研究也给我们带来了对教育领域的勃勃生机,我们可以通过追踪在线学习过程中学生跟学生之间、学生跟老师之间、学生的操作行为等等来解析学生的个性特征、情绪特征、动力特征等等,以帮助我们更好的因材施教,或者给它推荐最适合他的学习内容。当然这些信息更大的价值是反馈给老师、反馈给家长,让老师更多的了解孩子,用最适合他的方式激励他,让家长更多了解孩子,转变他的教育和教导的方式。
大数据也有美丽的陷阱
大数据确实改变了我们的教育很多很多,但是话说回来,我还想强调一下,大数据虽然很美,很有价值,也有意义,但是它也有美丽的陷阱,体现在以下一些方面,我只是简单的罗列:
在教育领域到底我们要采集哪些数据?数据太多了,如果没有一些教育理论的支撑,有时候这些数据到底能发挥多大的价值,我们划个问号。
非文本数据我们如何更好的做识别跟处理,可能有赖于自然语言技术等等更加进一步的发展。
我们的数据如何降噪,这里我要提一句,因为现在很多公司做作业场景、练习场景的数据收集,收集完了确确实实可以给孩子反馈报告“你的孩子哪里掌握了哪里没有掌握”但是我们不得不关注一点,咱们这个数据对于评价一个孩子有没有噪音,比如如果在考试环境中和作业环境中,孩子的数据表现是否会一样?如果是在无监督的环境中和有监督的环境中孩子的数据表现是否会一样?所以如何把采集来的数据做评价之前做降噪,这也是我们非常关注的话题。
教育大数据到底如何挖掘,如何建模?
我们如何避免数据推论的错误?我们看到很多老师,我们给孩子,尤其我很害怕给中学生做心理测试或者性格测试,害怕原因是老师会误读结果,因为我们知道中学生的性格是不稳定的,它随时在变化,但是我担心这个数据报告拿到老师手里,老师说“这个孩子不自信、这个孩子内向这个孩子是粗心的”立刻成为他给孩子贴上的标签,标签效应对孩子影响是巨大的。这是大数据我们要避免一些美丽的陷阱。
大数据的第二重价值:精准人才匹配
接下来我要讲一讲大数据第二重价值,有了大数据可以实现精准人才的匹配。
我们可以看到当我们从孩子小的时候在他幼儿园甚至于一出生就伴随着对他数据的搜集跟采集,从K12到大学一直到求职,那么我们自然而然就可以在迭代动态中构建个体的所谓的才智发展图谱,刚才我也谈到了不仅仅有知识、技能、能力,还有个性、价值观、动机等等,随着他的成长这些才智图谱逐步的迭代,动态的发展,直到18、20岁左右开始慢慢的稳定甚至到职场以后开始趋向成熟。
有了这个图谱最大的好处是,我们可以实现人和专业、人与职业真正的、精准的匹配。我了解了这个学生、这个孩子,我们又了解高校每个专业对人才的需求或者职场每个岗位对人才的需求,那么就很容易实现人才精准的匹配,有数据库以后就可以实现这样的价值。
因此这里也做一个小广告,ATA刚刚和南京大学成立了大学生双创人才素质研究中心,这个双创人才素质研究中心我们的目的是通过在南京大学的试点形成一个双创型优质人才的数据库,未来企业再挑双创人才的时候不用自己考试、自己招聘,直接从这个数据库里去匹配、去挑选最适合他的双创的人才,这是我们现在在做的很重要的一个项目。
因此大数据链接贯通了个体的学习,到升学到职业的发展,ATA未来的十年二十年一直致力于做的事情就是构建教育与学习、人才和职业的数据中心,通过我们的测评技术、通过我们积累的大数据、通过我们的知识图谱的研究和构建。
最后总结一下,我今天想阐述的就是大数据对于教育的两大价值,一个是我们要通过大数据提升学生的学习成效,我们要通过大数据实现人才的精准匹配,换个角度说,其实更简单的阐述一个是更好的因材施教,一个是让人尽其才,这正是ATA未来想要致力于利用大数据对教育做的努力和希望可以做出的贡献。
戳这里查看所有嘉宾精彩演讲,立即永久保存,【印象笔记企业版】友情支持 。